Operativní temporální datový sklad
(Operational Data Warehouse)
PRINCIPY
Petr Vršek, Tomáš Vršek - SOFTMODEL, Dobrovského 32, 170 00 PRAHA 7
Obsah
ÚvodOdborná veřejnost může čerpat zajímavé informace o dimenzionálním modelu a o datovém skladu (Data Warehouse - DW) např. z [1] a o operativním datovém úložišti (Operational Data Store - ODS) např. ze [6].
Oba výše uvedené prameny jsou sice inspirující, ale nesplňují naše dávné představy o tom, jak má databáze podnikového informačního systému vypadat.
Pramen [7] pojednávající mimo jiné o temporálních databázích, ukazuje zcela jasně význam časového pohledu a možnosti jeho evidence. Citace z tohoto pramene: "Čas je vše prostupující aspekt reality. Události se vyskytují jako specifické body v čase. Objekty a vztahy mezi objekty existují v průběhu času. Schopnost modelovat časovou dimenzi reálného světa je zásadní pro mnoho počítačových aplikací, jako např. účetnictví, bankovnictví, inventarizace, ekonometrie, právo, zdravotnictví, pozemkové a geografické informační systémy, rezervace letenek."
Vzhledem k vlastním zkušenostem s návrhem databázových schémat v nejrůznějších aplikačních oblastech tvrdíme, že výše uvedený seznam by bylo potřeba rozšířit na všechny obory lidské činnosti evidované počítači, protože realita taková je. Nejhorší, co můžeme udělat, je tvrdit, že u některého oboru temporalitu nemusíme evidovat "protože jí moc není" a "obtížně se to programuje".
Díky soustavnému ignorování temporality téměř ve všech běžných podnikových informačních systémech dochází ke zbytečným vícenákladům a nesmyslně složitým postupům díky zákonitě a stále vzrůstající datové nekonzistenci, díky nutným opatřením v oblasti zbytečné archivace dat a zbytečné tvorby nového software operujícího nad archivními daty uloženými jinak než data provozní.
Provozní systémy věšinou potřebují operovat jak nad daty starými, tak nad aktuálními, tak i nad těmi, které již existují, ale teprve vstoupí v platnost, dá se tedy říci nad daty budoucími. Jelikož jsou běžné provozní systémy naprogramovány tak, že se historií kvůli jednoduchosti nezabývají, bývá výsledek práce referentů používajících takovéto informační systémy velmi žalostný.
Na základě našich dvacetiletých zkušeností s databázovým modelováním navrhujeme nový model - ODW (ve našich starších článcích nazývaný též jako OLTP DW), který je především temporální databází ukládající operativní data s evidencí dvou časových intervalů (validity time / transaction time). Data dělíme na data dimenzionální a na fakty. Struktura datového skladu je podobná (nikoliv totožná) klasickému dimenzionálnímu modelu popisovanému panem Ralphem Kimballem v [1] a účel tohoto skladu je podobný (nikoliv totožný) s operativním datovým skladem popisovaným panem Billem Inmonem v [6].
ODW se liší od představ pana Kimballa především tím, že eviduje provozní data, čili že i když se jedná v principu o dimenzionální model (DM) uložení dat, přesto se tento datový sklad používá (mimo jiné) přímo jako provozní databáze běžných aplikací.
ODW se liší od představ pana Inmona především tím, že i když se též jedná o operativní datový sklad (ODS), je dokonale tepmorální a naší snahou je, využívat jej přímo jako datové úložiště jednotlivých aplikací.
K odvážnému kroku realizace nového systému na základě nového modelu jsme se odvážili teprve tehdy, až výkon relačních databázových serverů a prudce klesající cena diskových polí umožnily splnit náš dávný cíl:
1. Data i veškeré vztahy mezi daty ukládat správně, neredundantně, s dokonalou evidencí změn všech hodnot v čase a s možností jakýchkoliv oprav aniž staré hodnoty zmizí. Zde se v žádném případě nepodřizovat provozním požadavkům na rychlost presentace, ale důsledně dodržovat navržené principy ukládání dat.
2. Současně ukládat vybraná data ještě jednou nebo vícekrát v takové formě, aby byla velmi rychle dostupná pro prezentaci. Pouze na vývojovém stupni techniky závisí, je-li nutno takovéto replikace vůbec či podmíněně vytvářet. V roce 2001 se domníváme, že většina presentačních dat ještě musí ve formě replikací - časových snímků - existovat.
ODW tedy ukládá data v podstatě dvakrát:
Poprvé jednak optimálně co se týče kvality uložení (žádná redundance) a dokonalé temporality, jednak relativně špatně co se týče rychlosti presentace.
Podruhé jednak optimálně co se týče rychlosti presentace, jednak velmi špatně co se týče kvality uložení (velká redundance) a temporality (žádná teporalita - jedná se o časový snímek v jednom okamžiku).
Řídící systém datového skladu se skládá jednak z grafického editoru sémantické sítě, umožňujícího navrhnout a doplňovat logickou strukturu vlastního datového skladu, dále pak z generátorů programového kódu. Část generovaného kódu umožňuje vytvořit a udržovat fyzickou strukturu databáze (příkazy SQL-DDL). Další část je využívána aplikačními programy ke snazšímu přístupu ke komplikovaným strukturám databáze ODW a konzistentním modifikacím jejího obsahu (příkazy SQL-DML a uložené procedury). Struktura metadat odpovídá všem těmto funkcím a je snadno rozšiřitelná.
Základní vysvětlení některých pojmů
DW (Data Warehouse), datový sklad
ODS (Operational Data Store), provozní datové úložiště
ODW (Operational Data Warehouse), datový sklad pro provozní systémy
Nové paradigma které navrhl Ing. Petr Vršek. Jedná se o databázovou strukturu v principu založenou na dimenzionálním modelu (rozeznává též dimenze a fakty), ale mající především tyto základní odlišnosti či specifika:
ODW MS (Operational Data Warehouse Management System)
Systém řízení ODW ukládá svá data v metadatabázi ODW a plní následující funkcionalitu, která bude v rámci vývoje nadále rozšiřována:
Grafický editor sémantické sítě ODW
a) definice a editace dimenzionálních uzlů dimenzí
b) typizace dimenzionálních uzlů
c) definice a přiřazování faktů dimenzionálním uzlům
d) disjunkce typizací
e) tvorba gen-spec vazeb typizací
f) tvorba asociačních vztahů typizací
g) hierarchizace dimenzionálních uzlů
h) HTML grafické výstupy sémantické sítě šiřitelné po Internetu
Generátor fyzických struktur ODW
a) generátor úplné struktury
b) generátor změn struktury
Podpora aplikační logiky
Podpora tvorby SQL příkazů na základě dat v metasystému
a) tvorba dotazů na definované fakty a časové intervaly na základě dimenzionálních diagramů
b) generátor uložených procedur pro vkládání instancí dimenzionálních uzlů včetně povinných faktů, vkládání a modifikace ostatních faktů
Podpora integrace externích aplikací
a) metodika integrace pro různé případy
b) rozšíření metasystému o externí systémy
c) poloautomatická párovačka dimenzionálních prvků
d) procedury pro verifikaci údajů v externí databázi dle dimenzionálního prvku ODW
e) podpora obousměrné replikace
Procedury pro interní slučování dimenzionálních prvků
Podpora modifikací a dotazů ve zvoleném čase
a) podpora modifikace faktů v čase
b) podpora dotazů ve zvoleném čase
Dimenze, dimenzionální prvky, informační prostor
Dimenzionální uzel, struktura (skelet) dimenze
Fakt (s vazbami k libovolnému počtu dimenzí)
Vazební fakt
Metadatabáze ODW
Sémantická síť (Semantic Net)
vztahy typizační
vztahy asociační
Tato kapitola popisuje postupně klíčové prvky ODW, přičemž se popis soustředí na jednotlivé vlastnosti ODW a srovnává je s běžnými metodami návrhu databázově orientovaných informačních systémů.
Dimenze, typizace, uživatelská typizace
Pojem dimenze je v rámci ODW používán pro množinu kódů vždy co nejobecnějšího číselníku. Každý z nich tvoří jeden z rozměrů informačního prostoru, jehož součástí jsou ostatní údaje - fakta.
Dimenze, které jsou základem každé sémantické sítě, můžeme podle složitosti členit následovně:
Některé dimenze nazýváme nomenklaturami. Nomenklaturou v terminologii ODW nazýváme takovou dimenzi, která uživatelským způsobem typizuje jinou dimenzi. Příkladem budiž nomenklatura "památkových objektů", která uživatelsky typizuje "objekty" (jiná dimenze !). Zde zdůrazňujeme pojem uživatelská typizace. Tento typ typizace neovlivňuje programové vybavení: Nomenklatura může být uživatelsky aktualizována, aniž je třeba upravit algoritmus zpracování či uživatelskou obrazovku. Uživatelská typizace se do sémantické sítě nezakresluje.
Opakem této typizace je systémová typizace. Vytváří ji zásadně designer systému či analytik Systémová typizace se zakresluje do sémantické sítě (příklady: subjekt "fyzická osoba", subjekt "právnická osoba", komunikační prvek "telefon", komunikační prvek "email",...) a ovlivňuje programové vybavení. Systémová typizace ovlivňuje algoritmus aplikací resp. vzhled uživatelských obrazovek.
Dimenzi v našem smyslu si lze představit také jako nadtřídu objektů příbuzného typu. Graficky je ovšem obsah metaschématu znázorňován jako sémantická síť, nikoli jako diagram tříd (UML) či ER-diagram. Zavedení vlastní notace je nutné vzhledem k podstatným odlišnostem sémantiky dimenzionálního modelu od běžného objektového modelu. Odlišné a společné rysy zde budou vysvětleny na běžně užívaném diagramu tříd, který je součástí všech objektově orientovaných metodik.
Stejně jako v diagramu tříd pomocí dědičnosti, lze v sémantické síti ODW díky typizaci dimenzionálních prvků odlišit v systému evidované, jednoznačně identifikované objekty příbuzného typu. Například “subjekt” má typizaci či podtřídu “fyzická osoba”. Typizace v našem smyslu má ovšem oproti klasickému vztahu dědění navíc dvě podstatné vlastnosti:
S násobnou dědičností často vznikají potíže při implementaci metod v objektově orientovaných jazycích, proto ji mnozí doporučují používat v minimální míře. V případě ODW jde ale o speciální databázově orientovaný systém, jehož funkce pro manipulaci s daty jsou většinou automaticky generovány pro každý dimenzionální uzel s ohledem na všechny navazující datové struktury. Problémy jsou tak minimalizovány a využití násobné typizace spolu s její proměnlivostí v čase je jednou z hlavních výhod ODW při modelování reálného světa.
Každá typizace definovaná nástrojem pro řízení datového skladu - grafickým editorem sémantické sítě - SOFTMODEL ODW MODELERem - je součástí metadat ODW. Je určena pro přímé využití v aplikačních programech, jejichž algoritmy se rozhodují právě na základě typizace dimenzionálních prvků. Měla by být dobře promyšlena právě s ohledem na použití aplikacemi integrovaného IS a v čase by se neměla příliš měnit (viz. kapitola “Verze, konfigurace, distribuovaný vývoj”). Tuto typizaci nazýváme též systémovou a definuje ji databázový návrhář spolu s vývojáři aplikačního SW.
Uživatelská typizace je naopak definována uživatelem či importována z externích systémů, není součástí metadat a přímo na ní nesmí záviset funkce aplikačních programů. V ODW je realizována jako speciální typizační dimenze. Ta představuje libovolně strukturovaný číselník, který je navázán pomocí vazebního faktu na uživatelsky typizovanou dimenzi.
Typizační dimenze (nomenklatura) má ovšem na rozdíl od běžných dimenzí jednu speciální vlastnost. Jejím prvkům lze přiřadit systémovou typizaci té dimenze, která je pomocí nomenklatury typizována (čili dimenze ve které je číselník použit). Uživatel tak může své číselníky libovolně měnit, aniž by zasahoval do funkce systému, a přitom si pro každou hodnotu z číselníku může definovat jaké kombinaci systémové typizace nejlépe odpovídá. To je činnost příslušející zejména zodpovědnému správci číselníku. Když pak koncový uživatel zařadí dimenzionální prvek pouze podle uživatelského číselníku, aplikuje se automaticky rovněž předdefinovaná typizace systémová.
Fakta, alternativní klíče
Jestliže použití dimenzí a dimenzionálních uzlů v ODW přibližně odpovídá hiearchiím tříd v objektovém modelu či typizacím entit v datovém modelu, je nutné mapovat nějakým způsobem ještě jejich atributy, tedy konkrétní údaje vztahující se k třídě, resp. entitě. Bez nich nelze databázi naplnit smysluplným obsahem.
Údaje závisející na dimenzionálních uzlech nazýváme fakta. Analogicky v objektovém nebo ER modelu závisí atributy na svých třídách. Od atributů užívaných v objektových (resp. datových) modelech se však fakta v ODW také v mnohém odlišují, díky čemuž je nutné používat nejen rozdílnou notaci, ale hlavně způsob návrhu schémat.
Jednotlivá fakta tedy mají v ODW relativně samostatnou roli a vzhledem k jejich výše uvedeným vlastnostem je v databázi každý fakt reprezentován svojí vlastní tabulkou.
Další problém, který je v metodice a implementaci ODW řešen specifickým způsobem tak, aby odpovídal reálnému provozu integrované databáze, je jednoznačná identifikace dimenzionálních prvků pomocí klíčů.
Většina databázových aplikací samozřejmě klíče používá a to jak klíče přirozené (rodné číslo, IČO atd.), tak i generované (různé identifikátory vět, OID atd.). Samostatné použití generovaných klíčů je problematické, protože nezabraňuje duplicitám při vkládání objektů reálného světa do databáze. Proto je v každém případě žádoucí při vkládání kontrolovat jedinečnost vět podle přirozených klíčů. Zde ovšem mohou nastat potíže, pokud konkrétní dimenzionální prvek (analogicky objekt) musíme povinně jednoznačně identifikovat pouze jedním z několika možných způsobů. Pokud předem určíme, že se bude pro daný dimenzionální uzel používat pouze jeden typ klíče (skupina klíčových faktů), může být uživateli pouze kvůli nedostatku informací zabráněno dimenzionální prvek založit nebo dokonce záměrně založí chybná data, aby se potížím vyhnul. V klasické databázi se například často požaduje k identifikaci fyzické osoby rodné číslo a pokud není k dispozici, nelze daný subjekt vůbec evidovat.
V ODW lze pro každý dimenzionální uzel definovat i několik alternativních klíčů, které se skládají z libovolných faktů vázaných na danou dimenzi. Při založení dimenzionálního prvku lze znát pouze některý z těchto alternativních klíčů (například “Jméno+Příjmení+Bydliště+Datum narození” nebo “Rodné číslo+Příjmení”). Pro každý vkládaný prvek pak musí být jakýkoli použitý klíč v daném čase jedinečný. Přitom se může stát, že fakta, která jsou součástí některého z alternativních klíčů, nebudou pro určité prvky zadána a při kombinovaném používání různých alternativních klíčů dojde k duplicitám. Tomu sice nelze ve všech případech z podstaty věci zabránit, nicméně tomuto problému můžeme systematicky čelit pomocí inteligentních vkládacích algoritmů a řešit ho, pokud již vzniknul, pomocí slučování dimenzionálních prvků.
U existujícího prvku může navíc dojít k doplňování faktů a ke změnám. Při modifikaci faktu, který je součástí některého z klíčů, bude uživatel v případě potřeby upozorněn na vznik duplicity a správce dat následně obdrží návrh na sloučení právě zjištěných duplicitních prvků.
Asociace, hierarchie
Jak bylo již bylo naznačeno v předchozí kapitole, vztahy mezi dimenzionálními uzly modelujeme pomocí vazebních faktů. Každý fakt, který závisí na více než jednom dimenzionálním uzlu, tvoří vazby mezi prvky těchto uzlů a představuje asociační vztah. Takto lze modelovat vztahy s libovolnou multiplicitou (kardinalitou), tedy vztahy typu “1:n” i “m:n”.
Jeden z uzlů, na kterém fakt závisí, přitom vždy označíme jako primární. To má význam z hlediska přehlednosti schématu a implementace v databázovém systému (využití clusterů pro fakta jednoho dimenzionálního uzlu). Primárním uzlem musí být ten, na kterém fakt závisí povinně. Dalším kritériem pro volbu primárního uzlu je co nejnižší multiplicita ve vztahu uvažovaného uzlu k faktu, tedy aby k dimenzionálnímu prvku tohoto uzlu existovala v jednom čase průměrně jedna nebo několik málo instancí vazebních faktů.
Volba primárního uzlu každopádně nemá vliv na logiku návrhu datového skladu a ani z hlediska tvorby aplikací neexistují mezi primárním uzlem faktu a ostatními uzly žádné podstatné rozdíly.
Speciálním způsobem jsou v ODW modelovány hiearchické (whole-part) vztahy mezi uzly jedné dimenze. Ty není praktické definovat jako běžné vazební fakty, protože skupina všech těchto vazebních faktů, spojujících vždy dva uzly, tvoří dohromady jednu strukturu. Tu je vhodné společně označit (např. “organizační struktura”, “územní struktura”), zakreslit a popsat. Nad obecně utvořenou hiearchickou strukturou pak také budou pracovat algoritmy (často rekurzivní), které mohou být řízeny její definicí v metaschématu. V rámci celé hiearchické struktury se v databázi používá jedna fyzická tabulka pro vazební fakty.
Definici každé vazby v hiearchii lze upřesnit podtypováním této vazby, takže je možné hiearchické struktury i aplikační programy navrhovat obecně a teprve při konkrétní implementaci určit přesnější pravidla. V organizační struktuře například obecně definujeme, že organizační jednotka je navázána na jinou organizační jednotku. Upřesněním této vazby je, když například každé oddělení musí být navázáno na odbor, přičemž oddělení i odbor jsou podtypy organizační jednotky.
Distribuovaný vývoj, verze, konfigurace
ODW je svými vlastnostmi předurčen k tomu, aby mohl evidovat konzistentním způsobem klíčová data organizace po delší časové období a přitom bylo možné postupně reagovat na měnící se požadavky. S tímto cílem byl i navržen.
Proto je nutné kromě popisu struktury ODW k určitému okamžiku v metasystému umožnit i její postupné rozšiřování a zpřehlednit implementaci těchto změn. V úvahu je nutné brát i účast více skupin vývojářů a uživatelů na tomto procesu.
Ideálním stavem z hlediska integrace a kompatibility aplikací napříč provozovateli ODW je, aby probíhal společný vývoj jednotné struktury ODW interaktivně nad jednou metadatabází. S použitím sítě Internet je tento způsob návrhu i uskutečnitelný. Z různých důvodů - organizačních, obchodních a v neposlední řadě z důvodu existence rozdílných požadavků a názorů jednotlivých uživatelů není však spolupráce na jednotném projektu vždy reálná. Přesto jsme navrhli strukturu metadat takovým způsobem, aby umožnila různým uživatelům používat základní společné prvky systému ODW, odděleně přidávat vlastní rozšíření a zpětně využívat rozšíření ostatních uživatelů.
Základním identifikačním prvkem umožňujícím distribuovaný vývoj je unikátní číslo serveru, na kterém jsou umístěna aktualizovatelná metadata (server kde probíhá vývoj struktury ODW). To má přiděleno každá organizace nebo skupina organizací, které vyvíjejí metasystém společně a mají pro něj vytvořen společný server. V rámci tohoto identifikátoru (atribut SERVID v mnoha tabulkách metasystému) jsou dále zakládány všechny struktury ODW. Proto lze pak navzájem slučovat a přenášet subschémata vzniklá na libovolném místě bez kolizí. Některé konstrukty lze upravovat pouze v místě jejich vzniku (například přidávání faktů k dimenzionálním uzlům), jiné můžeme rozšiřovat na libovolném jiném serveru (například napojení vlastních dimenzionálních uzlů na uzly vniklé jinde nebo vytvoření hiearchické struktury nad dimenzionálními uzly definovanými na jiném místě). Kolizím v názvech generovaných tabulek lze v závislosti na implementaci předejít např. pomocí více “schémat” v jedné databázi (řešení pro Oracle) nebo číselnou příponou v názvu tabulek. Návrh se řídil tím, aby vzájemná spolupráce nebyla příliš omezena, ale přitom nevznikly problémy po zařazení cizího subschématu do vlastního systému. Pokud se se sdílením aplikací a výměnou dat s jinými ODW nepočítá, není vůbec nutné tuto možnost využívat. Společný server pro vývoj ODW nemusí být shodný s databázovým serverem, kde je ODW provozován. Na jednom vývojovém serveru lze také připravit implementaci více provozovaných ODW, na nichž je pak umístěna pouze replika metadat určená ke čtení.
Systém správy verzí je v ODW navržen tak, aby byl umožněn plynulý inkrementální vývoj. Přitom je však přesně definován obsah jednotlivých verzí systému a jsou respektovány role jednotlivých tvůrců na rozvoji systému. Modifikace datové struktury jsou umožněny jen do té míry, aby umožnily zpětnou kompatibilitu aplikací.
V rámci každého serveru, na kterém probíhá vývoj je samostatně vytvářena souvislá řada verzí. Každá verze je evidována a můžeme popsat, jaké změny obsahuje. Při práci s metasystémem pak vždy zvolíme verzi na které pracujeme. Podle toho, v jaké fázi vývoje se daná verze nachází, je různým skupinám uživatelů umožněna nebo zakázána modifikace metadat.
Rozlišujeme 3 stavy u každé verze struktury ODW:
Návrháři databáze je umožněno provádět libovolné změny včetně mazání, ale pouze nad prvky struktury vzniklými ve verzích, které jsou dosud v tomto stavu. Jde vždy o nejnovější nebo budoucí plánované verze. Ostatní vývojáři mohou v této fázi sledovat návrh struktur a připomínkovat ho. Pokud je nová struktura ustálena, následuje vývoj aplikací, které ji používají.
Pokud je verze v této fázi, nelze již zásadním způsobem modifikovat struktury které v rámci ní vznikly, ale lze měnit některé její parametry (například datové typy faktů). Tyto změny může provádět jak návrhář databáze, tak i programátor aplikací. Přitom se podle potřeby mění struktura databáze ODW na serverech, kde je aplikace vyvíjena.
Změny provedené v rámci verze jsou implementovány do provozovaných databází ODW. Vývoj verze je ukončen a nelze v rámci ní provádět žádné změny struktury. Nové aplikace samozřejmě mohou být vyvíjeny i nad staršími verzemi struktury, zpětná kompatibilita je zajištěna. U každé aplikace je vhodné definovat, jakou část schématu používá a jakou minimální verzi vyžaduje (viz. balíčky)
Každá verze postupně projde stavy návrhu a vývoje, poté se stanou změny v ní provedené stabilní součástí struktury ODW. V jednom okamžiku jsou například verze 1..3 implementovány, verze 4..5 jsou ve fázi vývoje aplikací kvůli nimž byly změny struktury naplánovány a verze 6 je zatím pouze ve stavu návrhu budoucích změn.
Z informativních důvodů lze jednotlivé prvky struktury OLTP DW označit číslem verze, od které pozbývá jejich používání smysl. Kvůli zpětné kompatibilitě aplikací jsou ale vždy ve struktuře databáze zachovány.
Mezi různými metasystémy (viz. distribuovaný vývoj) lze sdílet pouze stabilní verze ve stavu implementace.
Kromě verzí zavádíme i možnost vytváření balíčků. Podobně jako jsou softwarové balíčky moderní metodou instalace programového vybavení, slouží datové balíčky ODW k přehledné implementaci databáze u koncového uživatele. Při implementaci systému můžeme na základě aplikačních balíků, které uživatel vyžaduje, vybrat i příslušná subschémata datového modelu (datové balíčky) a vytvářet tak na různých místech specifické konfigurace. Struktura ODW tak není monolitická, ale lze ji členit do oblastí, které se mohou vzájemně překrývat. Obsah balíčků se může v nových verzích systému rozšiřovat. V určité verzi má však každý balíček všude shodný obsah. Lze ho rozšiřovat pouze na místě, kde vznikl, ale může obsahovat i prvky vzniklé jinde.
Balíčky slouží i výměně subschémat mezi více vývojovými servery. Spolu se všemi daty, náležejícími do balíčku (v určené definitivní verzi) se exportují/importují i informace o stavu stávajících verzí v rámci serveru.
Integrace s externími databázemi
Přestože ODW může sloužit libovolnému aplikačnímu systému k ukládání všech dat, je jasné, že zejména při zavádění, ale i v pozdějším provozu bude nutné integrovat množství dat z externích systémů i jednoúčelových aplikací. Proto je v metasystému ODW zabudována podpora integrace externích aplikací a zejména podpora funkcí pro import/export dat do/z datového skladu.
Ke každému typu externího systému definujeme datové množiny, které představují buď přímo tabulky, SQL dotazy nebo výsledky práce uložených procedur. Všechny takto definované datové množiny jednoho typu externího systému nazýváme “externí schéma”. Každou datovou množinu pak přiřadíme některému z dimenzionálních uzlů ODW, s nímž budeme synchronizovat data.
Potom namapujeme vybraná pole datové množiny na fakta, která lze evidovat k dimenzionálnímu uzlu. Lze mapovat jak běžné fakty, tak fakty jež jsou součástí alternativních klíčů. Speciální postavení mají ta pole externí databáze, která představují v čase neměnný jednoznačný identifikátor prvku.V tom případě můžeme udržovat pomocí externího systému všechna fakta dimenzionálních prvků včetně alternativních klíčů (tedy v podstatě kompletní údržba dimenze). Jinak lze importovat pouze neklíčové fakty a prvky se párují právě na základě alternativních klíčů. Externí datová množina musí mít namapován minimálně jeden kompletní alternativní klíč příslušného uzlu.
Procedury generované pomocí ODW MS na základě těchto metadat budou umožňovat importním aplikacím zejména vyhledávat odpovídající dimenzionální prvky k řádkům externích tabulek a zajišťovat modifikaci namapovaných faktů.
Praktické příklady sémantických sítí
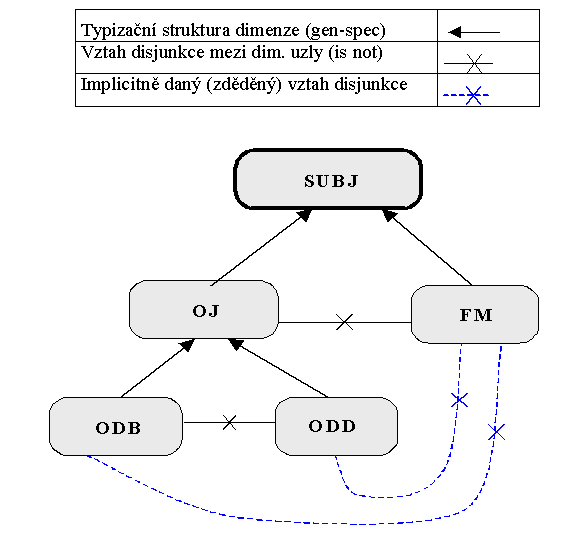
Příklad 1 představuje příklad jednoduché typizace subjektové dimenze v rámci podnikového informačního systému. Dimenzionální uzel "subjekt" (SUBJ) typizujeme v rámci struktury "gen-spec" na dimenzionální uzly "organizační jednotka" (OJ), "odbor" (ODB), "oddělení" (ODD) a "funkční místo" (FM)
OJ nemůže být v žádném případě současně FM. Proto mezi těmito uzly existuje vztah "is not".
Jestliže existuje vazba "is not" mezi rodičovskými uzly, existuje automaticky i mezi dceřinnými uzly a v sémantické síti se nezakresluje (zde na obrázku uvedeno kvůli vysvětlení čárkovaně).
Sémantická síť příkladu 1 vypadá následovně:
Příklad 2 představuje význam vztahů asociačních. Entita "subjekt" je typizována buď jako "organizační jednotka" nebo jako "funkční místo". Mezi organizačními jednotkami (organizační struktura - vzájemné vazby organizačních jednotek) a funkčními místy jednoho podniku existují dva typy hierarchických agregačních vazeb "whole-part" a to "organizační struktura" (ORG) a "poštovní struktura" (POST).
Sémantická síť příkladu 2 vypadá následovně:
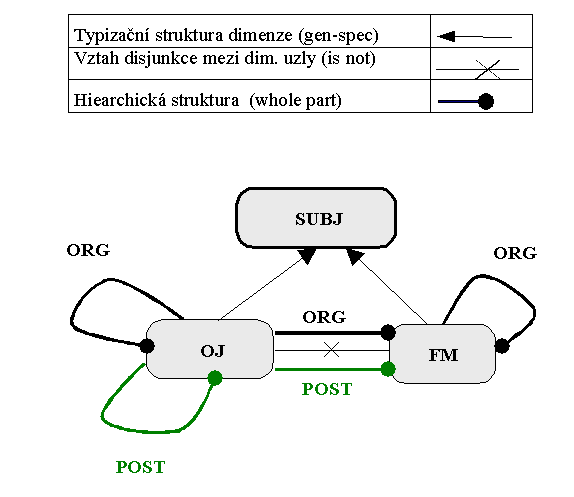
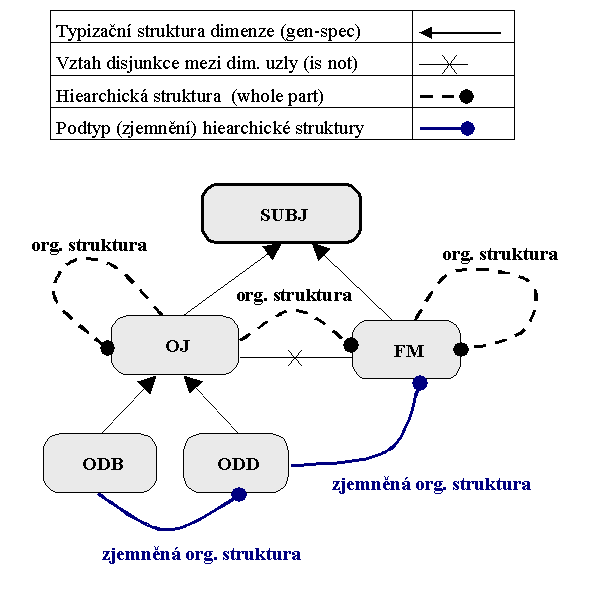
Příklad 3 demonstruje zjemňování asociační struktury typu "whole-part" z příkladu 2.
Představme si, že zjistíme, že dimenzionální uzel "organizační jednotka" (OJ) je příliš hrubý a že jej ještě podtypizujeme na "odbor" (ODB) a na "oddělení" (ODD).
Sémantická síť příkladu 3 pak vypadá následovně:
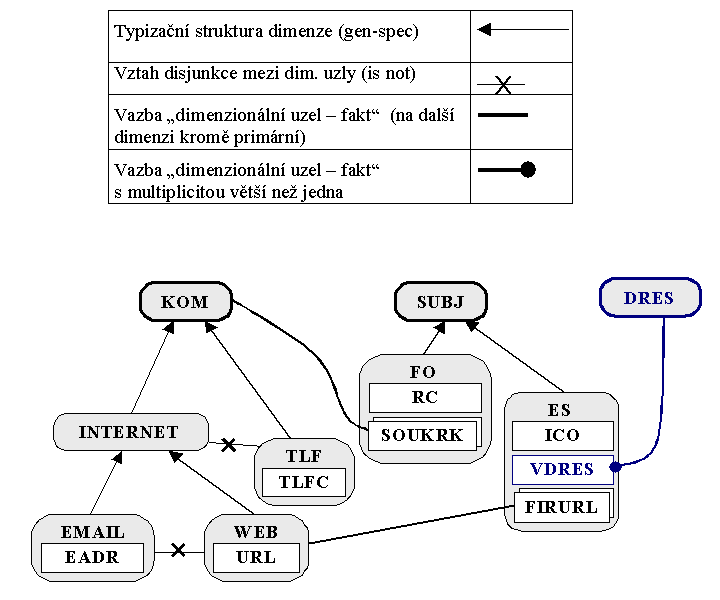
Příklad 4 vysvětluje závislost faktů na na dimenzích.
Dimenze:
SUBJ ... dimenze subjektová
DRES ... dimenze - nomenklatura - druhů ekonomického subjektu
KOM ... dimenze komunikačních prvků
Fakty (vysvětlení některých případů):
SOUKRK ... "soukromá komunikace" je vazební fakt mezi subjektem - fyzickou osobou - a libovolným komunikačním prvkem. Fyzická osoba může mít žádný až nekonečno komunikačních prvků různého typu (telefon, email, URL) v jednom čase, fakt musí mít vazbu na subjektovou dimenzi, je to primární dimenze z hlediska faktu. Komunikační prvek může být přiřazen žádné až jedné fyzické osobě v jednom čase, fakt musí mít vazbu na komunikační dimenzi, je to obecná dimenze z hlediska faktu.
VDRES ... "vazba na druh ekonomického subjektu" je vazební fakt mezi subjektem - ekonomickým subjektem a druhem ekonomického subjektu daným nomenklaturou. Ekonomický subjekt musí mít jednu a právě jednu vazbu na nomenklaturu druhů ekonomických subjektů v jednom čase, fakt musí mít vazbu na subjektovou dimenzi, je to primární dimenze z hlediska faktu. Nomenklaturní položka může být přiřazena žádnému až nekonečnu ekonomických subjektů v jednom čase, fakt musí mít vazbu na dimenzi druhů ekonomického subjektu, je to nomenklaturní dimenze z hlediska faktu.
FIRURL ... "firemní internetová stránka" je vazebním faktem mezi ekonomickým subjektem a komunikačním prvkem - webem. Firma může mít žádnou až nekonečno webových stránek v jednom čase, fakt musí mít vazbu na subjektovou dimenzi, je to primární dimenze z hlediska faktu. Webová stránka může být přiřazena žádné až jedné firmě v jednom čase, fakt musí mít vazbu na komunikační dimenzi, je to obecná dimenze z hlediska faktu.
Sémantická síť příkladu 4 vypadá následovně:
Příklad 5 vysvětluje význam alternativních klíčů a slučování dimenzionálních prvků.
Alternativní klíč je množina těch faktů (klíčových faktů), které jednoznačně definují existenci dimenzionálního prvku. V rámci jednoho dimenzionálního uzlu můžeme definovat více alternativních klíčů. Každý z těchto klíčů může zahrnovat fakty, které jsou disjunktní či konjunktní s fakty zahrnutými do jiných alternativních klíčů.
Příklad pro subjektovou dimenzi, dimenzionální uzel "občan ČR":
1. alternativní klíč: "RČ", "příjmení"
2. alternativní klíč: "jméno", "příjmení", "datum narození", "adresní místo stavebního objektu bydliště"
Definice alternativních klíčů slouží k ověřovanému zakládání dimenzionálních prvků do systému tak, aby nevznikaly duplicity těchto prvků v daném čase a gestoři dimenzí nemuseli zbytečně slučovat tyto duplicitní prvky navzájem.
Nutnosti slučování dimenzionálních prvků však lze principiálně velmi těžko zabránit, i když ji lze použitím klíčů omezit na minimum.
Sémantická síť příkladu 5 vypadá následovně:
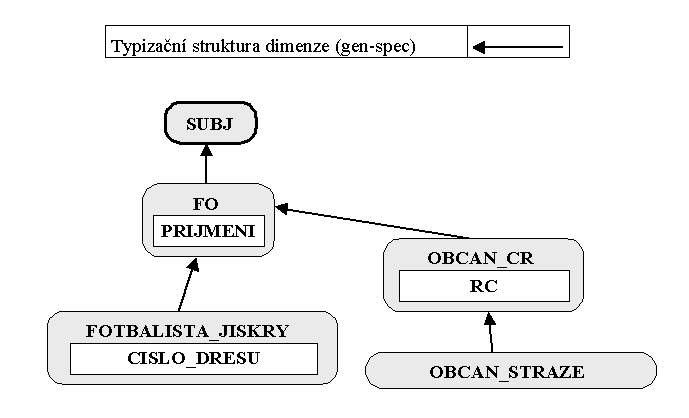
Vysvětlení problému:
V rámci podnikového integrovaného informačního systému budujeme nejdříve evidenci fotbalistů "Jiskry", přičemž definujeme jediný alternativní klíč s jedním klíčovým faktem "číslo dresu fotbalisty Jiskry" a příjmení jako neklíčový fakt. Typizaci "občan ČR" zprvu vůbec nebudujeme, protože nevytváříme evidenci obyvatel, ale evidenci fotbalistů vlastního klubu.
Po čase dostaneme za úkol evidovat navíc ještě obyvatele obce Stráž, v níž má sídlo fotbalový klub Jiskra. Vytvoříme další typizační větev a evidujeme občany Stráže. Definujeme pro ně jediný alternativní klíč se dvěma klíčovými fakty "RČ" a "příjmení".
Při evidenci občanů zakládáme nové subjekty. Kontrola ODW nás upozorní na to, že zakládáme občana, který již může být evidován v naší databázi jako fotbalista, protože nově zakládaný subjekt s ním má identické příjmení.
Referent může postupovat dvojím způsobem:
a) ověřit jakýmkoliv způsobem, že zakládaný subjekt je / není fotbalista Jiskry s příslušným číslem dresu a podle toho doplnit údaje k existujícímu subjektu / založit nový subjekt.
b) kvůli nemožnosti okamžitého zjištění skutečností založit nový subjekt s návrhem na možné sloučení a řešení přenechat datovému gestorovi na pozdější dobu. Datový gestor později subjekty sloučí (je-li občan evidovaným fotbalistou) či nesloučí (není-li tomu tak).
Závěr: ODW umožňuje předcházet zbytečné duplicitě dimenzionálních prvků a dojde-li již k ní z nejrůznějších důvodů, umožní tyto duplicity systémově odstranit.
Související produkty firmy SOFTMODEL s.r.o.
Desetiletá tradice: SOFTMODEL CASE
Grafický modeler databázových struktur používaný více než šedesáti firmami v ČR i na Slovensku. Vlastní metodika a na ní založené chování modeleru vede analytika k návrhu optimálního databázového schématu modelované předmětné oblasti. Existují generátory databázových objektů k většině současných relačních databázových systémů. Bližší údaje i stažení demoverze na naší webové stránce.
Aktuální novinka: SOFTMODEL ODW MODELER
(grafický editor sémantické sítě jako řídící rozhraní temporálního operativního datového skladu)
Definice a editace dimenzionálních uzlů dimenzí. Typizace dimenzionálních uzlů. Definice a přiřazování faktů dimenzionálním uzlům. Disjunkce typizací. Tvorba gen-spec vazeb typizací. Tvorba asociačních vztahů typizací. Hierarchizace dimenzionálních uzlů. HTML grafické výstupy sémantické sítě šiřitelné po Internetu.
Na základě našich dvacetiletých zkušeností s databázovým modelováním navrhujeme pro tvorbu podnikové integrované datové základny používat nový model, ODW (Operational Data Warehouse) nebo též OLTP DW (On Line Transaction Processing Data Warehouse), který je především temporální databází ukládající operativní data s evidencí dvou časových intervalů (Validity Time / Transaction Time).
Data dělíme na data dimenzionální a na fakty. Struktura datového skladu je podobná klasickému dimenzionálnímu modelu popisovanému Ralphem Kimballem (nikoliv totožná - ODW se používá jako provozní databáze!) a účel tohoto skladu je podobný účelu operativního datového úložiště popisovaného Billem Inmonem (nikoliv totožný - ODW eviduje dokonalou historii!).
Data i veškeré vztahy mezi daty se ukládají ve formě typizovaných dimenzionálních prvků a na nich závislých faktů s dokonalou evidencí změn všech hodnot v čase a s možností evidence jakýchkoliv oprav.
Vybraná data se současně ukládají ještě jednou nebo vícekrát v takové formě, aby byla velmi rychle dostupná pro prezentaci.
ODW doporučujeme budovat nad databázovým systémem ORACLE.
Budoucnost 2001/2002: SOFTMODEL ODW ENGINE
(aplikační rozhraní - ODW API)
Generátor fyzických struktur ODW. Podpora aplikační logiky. Podpora integrace externích aplikací. Procedury pro interní slučování dimenzionálních prvků. Podpora modifikací a dotazů ve zvoleném čase.
Řídící systém datového skladu se skládá jednak z grafického editoru sémantické sítě, umožňujícího navrhnout a doplňovat logickou strukturu vlastního datového skladu, dále pak z generátorů programového kódu. Část generovaného kódu umožňuje vytvořit a udržovat fyzickou strukturu databáze (příkazy SQL-DDL). Další část je využívána aplikačními programy ke snazšímu přístupu ke komplikovaným strukturám databáze ODW a konzistentním modifikacím jejího obsahu (příkazy SQL-DML a uložené procedury). Struktura metadat odpovídá všem těmto funkcím a je snadno rozšiřitelná.
[1] Kimball Ralph: A dimensional Modelling Manifesto. DBMS - August 1997 http://www.rkimball.com/html/articles.html - A Dimensional Modeling Manifesto, http://www.dbmsmag.com/9708d15.html - Drawing the line between dimensional modeling and ER modeling techniques
[2] Gardner Stephen: Data Warehouse Architectures. NCR Corporation 1997
[3] Vršek Petr: Quasi-nezávislé provozní databáze a dvouvrstvý datový sklad s využitím databází dimenzí. In: Sborník semináře “Datasem'99”, Brno, hotel Santon, 24.-26.10.1999, http://www.softmodel.cz
[4] Vršek Petr: Archetypy v temporárních databázích. In: Sborník semináře “Moderní databáze”, Mělník, 17. a 18.5.2000
[5] Schmuller Joseph: Teach Yourself UML in 24 hours, Sams, 1999 / Myslíme v jazyku UML, Grada, 2001
[6] William H. Inmon: White Papers - http://www.billinmon.com/cif/ods/kpods.html (resp. http://www.billinmon.com/cif/ods/kpods.html#ODS )
[7] Zaniolo, Ceri, Faloutsos, Snodgrass, Subrahmanian, Zicari: Advanced Database Systems, Morgan Kaufmann Publishers, Inc., ISBN 1-55860-442-X